在当今数据驱动的时代,随着能源行业数字化转型的深入,生物质能资源数据库信息系统已成为企业乃至国家能源战略的核心基础设施。面对海量的生物质原料数据、复杂的供应链信息、以及持续增长的监测与交易记录,传统单一数据库架构已难以满足高并发、低延迟、高可用的业务需求。因此,引入数据库分库分表技术,不仅是技术演进的必然选择,更是提升系统性能、保障数据安全、实现业务敏捷的关键路径。本文将深入剖析分库分表的核心原理,并基于大厂实践,为构建稳健、高效的生物质能资源数据库提供可落地的技术方案。
一、分库分表的核心原理:从集中到分布
分库分表的本质是将一个逻辑上庞大的数据库,通过特定规则,物理上拆分成多个独立的小型数据库(分库)或数据表(分表)。其核心目标在于分散单点压力,提升系统的整体处理能力和扩展性。
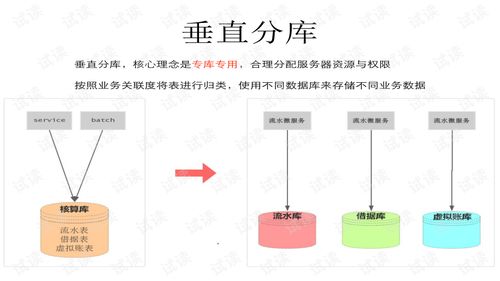
1. 分库:即垂直拆分或水平拆分。
- 垂直分库:按照业务模块划分。例如,将生物质能数据库拆分为:原料采集库(存储秸秆、林木等原料的产地、类型、产量)、加工生产库(存储气化、液化等工艺参数与能耗)、交易流通库(存储价格、合同、物流信息)。此举降低了单一数据库的复杂性,便于团队独立维护。
- 水平分库:将同一业务模块的数据分布到不同的数据库实例中。例如,根据地域(如华北、华东大区)将原料采集库进一步拆分,每个大区拥有独立的数据库服务器,实现负载均衡和数据隔离。
2. 分表:同样分为垂直与水平。
- 垂直分表:将一张宽表的列按访问频次或业务属性拆分。例如,将生物质原料的基础属性表(名称、热值、含水率)与动态监测表(实时温度、湿度、GPS坐标)分离,提升高频查询效率。
- 水平分表:将一张表的数据行按规则分布到多张结构相同的表中。这是应对海量数据的核心手段。例如,对年度原料交易记录表,可按时间范围(如每年一张表)或哈希取模(如根据原料ID的哈希值分配)进行拆分,极大缓解单表数据量过大导致的性能瓶颈。
关键技术点:分片键的选择至关重要。对于生物质能系统,常用的分片键包括:地理区域编码、原料唯一ID、时间戳(年-月)。需引入分布式数据库中间件(如ShardingSphere、MyCat)来透明化管理数据路由、跨库查询与事务,对应用层屏蔽底层复杂性。
二、生物质能数据库分库分表实践方案
基于大厂在超大规模系统架构中的经验,针对生物质能资源数据库,我们提出以下分阶段、多维度的实践方案:
第一阶段:架构设计与分片策略规划
1. 业务梳理与数据建模:明确核心实体(如“原料批次”、“生产设施”、“交易订单”)及其关系。分析数据增长趋势与访问模式(读多写少?联查频繁?)。
2. 分片维度确定:
- 以“地域+时间”为主维度:生物质资源具有强地域性和时序性。可先按省级行政区进行水平分库,库内再按年度或季度对核心事务表(如采集记录)进行水平分表。
- 以“业务类型”为辅维度:对相对独立、增长稳定的基础数据(如设备型号字典、化学组分标准),可采用垂直分库。
- 中间件选型与部署:推荐采用成熟的、社区活跃的中间件如Apache ShardingSphere。它支持灵活的分片策略、分布式事务(如Seata集成)、读写分离和数据加密,非常适合需要兼顾合规性与性能的能源信息系统。
第二阶段:数据迁移与双写方案
1. 平滑迁移:对存量数据,设计低停机时间的迁移工具。可采用“全量+增量”同步方式,先拷贝历史快照,再实时同步变更数据,在业务低峰期进行最终切换。
2. 双写过渡期:新老系统并行运行一段时间,确保新分片逻辑正确无误,并通过数据对比工具校验一致性。
第三阶段:应用改造与性能优化
1. SQL适配:避免跨多个分片的复杂JOIN查询和全局排序。对于必要的跨库查询(如全国范围内的原料热值分析),可考虑:
- 使用中间件提供的绑定表功能,将关联密切的表(如订单与物流)设置相同分片规则,使关联查询落于同一库内。
- 建立异步汇总的宽表或数据仓库(如基于Hive/ClickHouse),专供OLAP分析使用,与OLTP事务库解耦。
- 全局ID生成:摒弃数据库自增ID,采用分布式ID生成器(如雪花算法),确保跨分片ID的全局唯一性和趋势递增。
- 监控与治理:建立完善的监控体系,跟踪各分片的容量、QPS、慢查询。设置自动告警,并规划动态扩容流程(如增加新的地域分库)。
三、挑战与应对策略
- 分布式事务:生物质能交易可能涉及跨分片的资金与物流状态更新。解决方案:对于强一致性场景,可采用中间件支持的XA或Seata AT模式;对于最终一致性场景,可采用基于消息队列的补偿事务(Saga模式)。
- 历史数据查询:拆分后,查询多年前的全量数据可能变慢。应对:建立冷热数据分层,将超期历史数据归档至对象存储(如OSS)或低成本数据库,并提供统一查询接口。
- 运维复杂度:分库分表后,备份、监控、SQL调优的复杂度上升。应对:推行运维自动化,利用平台工具进行一键化部署、备份与数据校验。
##
分库分表是构建高性能、可扩展的生物质能资源数据库信息系统的核心技术架构。成功的实施始于对业务本质的深刻理解,成于精细的分片策略设计和平滑的迁移方案,并辅以持续的监控与优化。通过借鉴大厂沉淀的精品实践,结合生物质能行业数据地域性强、时序性明显、增长快速的特点,我们能够构建出一个既满足当前海量数据处理需求,又具备面向未来弹性扩展能力的坚实数据底座,从而为生物质能的科学开发、高效利用与精准管理提供强大的数据驱动力。